
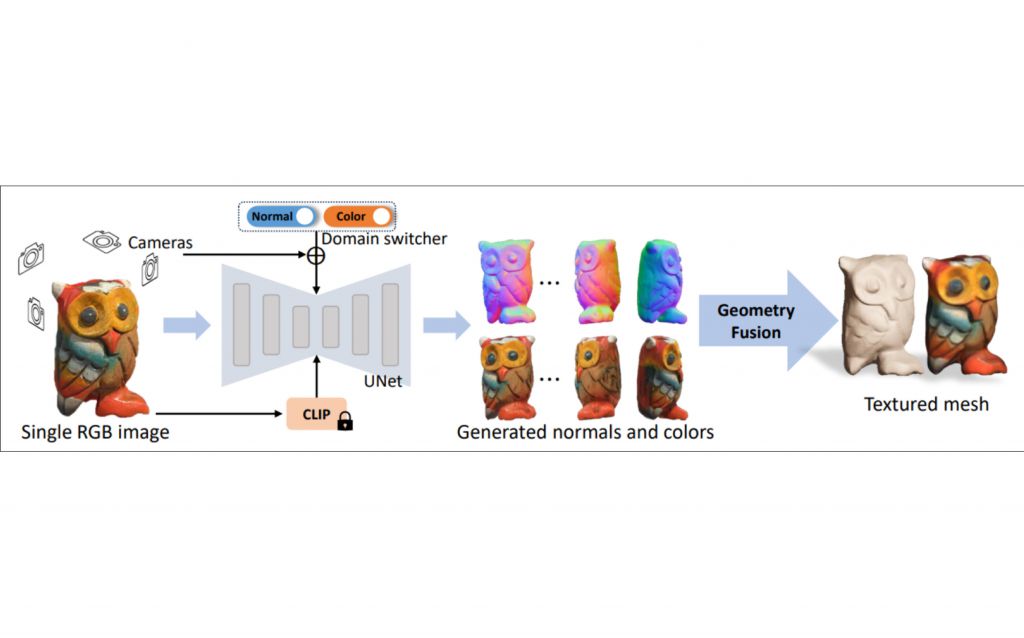
This technique transforms the 2D image into a three-dimensional representation. The method employs Cross-Domain Diffusion, a process where information is shared and diffused between different domains, enhancing the depth perception of the image.
By taking advantage of this technique, the system can deduce the three-dimensional structure of objects in the image, even if the original input was in a two-dimensional format.
This innovative approach opens the way for creating immersive 3D experiences from simple images, simplifying the transition from 2D to 3D in computer graphics.
Reference: Long, Xiaoxiao, et al. “Wonder3d: Single image to 3d using cross-domain diffusion.” arXiv preprint arXiv:2310.15008 (2023).
A sophisticated method in computer vision which involves taking multiple images of an object or scene from different viewpoints and then employing GC-MVSNet, a specialized algorithm, to reconstruct a detailed and accurate three-dimensional point cloud representation. GC-MVSNet algorithm excels at handling complex scenes, utilizing global context information to refine the reconstruction and improve the overall quality of the generated point cloud.
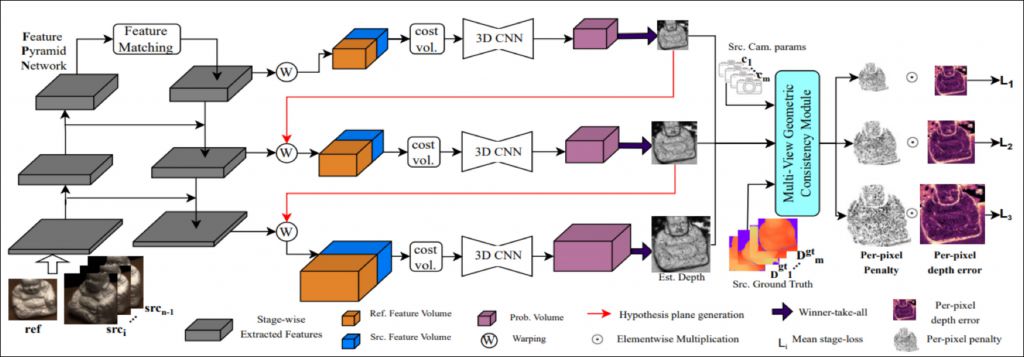 Figure 2. Overall Architecture
Figure 2. Overall Architecture
By combining information from multiple views, this approach enhances the depth perception and spatial accuracy, making it a powerful tool for creating realistic 3D models from a set of 2D images.

Reference: Vats, Vibhas K., et al. “GC-MVSNet: Multi-View, Multi-Scale, Geometrically-Consistent Multi-View Stereo.” Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. 2024.

This process involves capturing images of an object or scene from different angles and employing RayAug, a specialized algorithm, to convert the information into a detailed and textured 3D mesh.
RayAug optimizes the reconstruction by considering lighting and shading effects, resulting in a more realistic and visually appealing 3D representation. This method is particularly effective in creating accurate and intricate 3D models by leveraging the information gathered from multiple views, offering a powerful tool for generating lifelike 3D meshes from a set of 2D images.
Reference: Yao, Jiawei, et al. “Geometry-guided ray augmentation for neural surface reconstruction with sparse views.” arXiv preprint arXiv:2310.05483 (2023).
MENDNET
When dealing with objects that have missing or damaged parts, MendNet utilizes advanced algorithms to reconstruct a complete and accurate 3D model. This process involves analyzing the available information from various viewpoints and intelligently filling in the gaps or repairing damaged areas in the object’s structure.
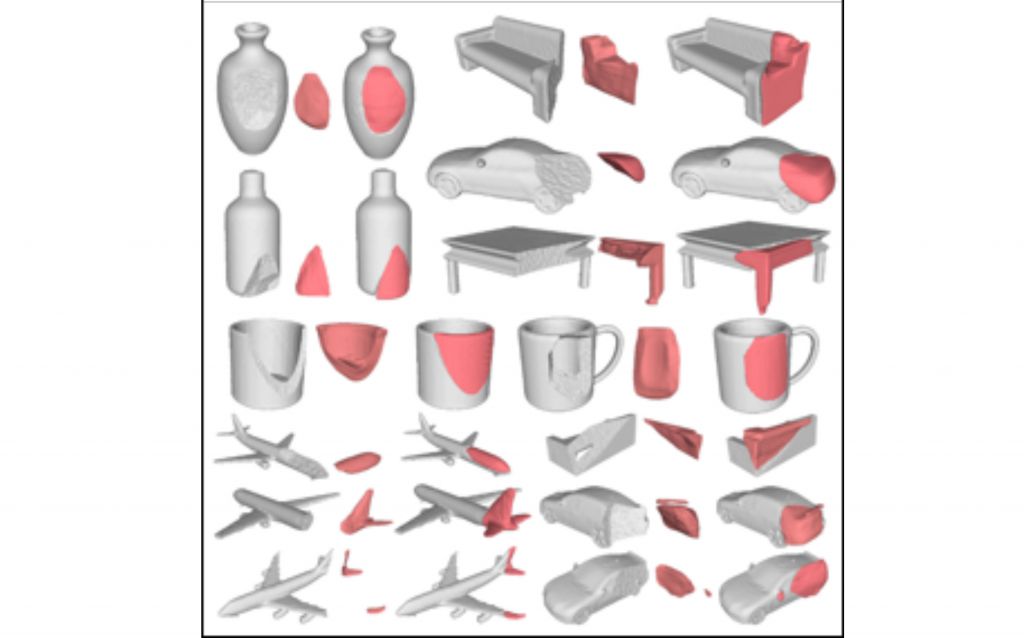
Reference: Lamb, Nikolas, Sean Banerjee, and Natasha K. Banerjee. “Mendnet: Restoration of fractured shapes using learned occupancy functions.” Computer Graphics Forum. Vol. 41. No. 5. 2022.
Pix2Repair
An advanced approach in computer graphics which facilitates 3D Reconstruction of objects that have missing or impaired sections. This method involves analyzing available visual data from different angles and intelligently filling in the missing or damaged parts of the object. Pix2Repair’s ability to restore the geometry of damaged objects makes it a valuable tool in the field of CH.

Tools and platforms that enable interactive and collaborative reconstruction efforts are emerging. Crowdsourced data, combined with expert contributions, transforms the reconstruction process into a joint effort. The following section presents some of the most advanced Open dataset of 3D scans of real world broken objects in cultural heritage.
Platform / SHREC 2021
SHREC 2021 provides a platform for researchers to showcase their advancements in the field of 3D shape retrieval. Participants utilize innovative methods to efficiently retrieve and match 3D models of cultural heritage objects, such as sculptures, artifacts, and monuments. The goal is to enhance the accuracy and effectiveness of retrieving relevant cultural heritage items from vast 3D shape databases.

Reference: Sipiran, Ivan, et al. “SHREC 2021: Retrieval of cultural heritage objects.” Computers & Graphics 100 (2021): 1-20
Dataset and methods / Pix3d
Pix3D is a dataset and methodology designed for modeling 3D shapes from a single image. The dataset includes images representing objects in various interior scenes, together with the corresponding 3D models. Researchers and developers use Pix3D to train and test algorithms capable of generating 3D shapes from a single 2D image. The methods employed involve teaching machines to understand the spatial structure of objects in photographs and translating this knowledge into precise three-dimensional representations.

Dataset / Fantastic Breaks
Fantastic Breaks is a unique dataset that consists of paired 3D scans of real-world broken objects along with their complete, undamaged counterparts. This dataset is invaluable in the field of computer vision and 3D reconstruction as it provides a diverse collection of objects that have undergone various types of damage.
Each pair of scans allows researchers and developers to study and train algorithms on reconstructing the original, intact state of objects from their broken versions. This dataset is particularly useful for advancing techniques related to object restoration, damage analysis, and understanding how 3D reconstruction algorithms perform in challenging scenarios involving damaged objects.
Reference: Sun, Xingyuan, et al. “Pix3d: Dataset and methods for single-image 3d shape modeling.” Proceedings of the IEEE conference on computer vision and pattern recognition. 2018.